
Introduction
Over the last couple of years we have witnessed more and more companies engage in exploring and even base their products and services on machine learning and big data.
Hence, engineering and orchestrating large data pipelines with a lot of moving parts has become unavoidable, often requiring to work in real time and in a completely automated fashion.
Various orchestration tools have been made available in order to make this easier, but in our opinion none offer as much control over sequencing, coordination, scheduling, and managing complex data pipelines from diverse sources as Apache’s open-source tool AirFlow. With an easy to use Web UI, this Python-based tool allows you to define your workflow in terms of DAGs – Directed Acyclic Graphs. It is easily integrated into Kubernetes and Celery for distributed computing, and unlike Cron Jobs for which you have to define the exact time of execution, tasks directly depend on the tasks that precede them and are executed when the upstream finishes, making it easy to write sequences of jobs, or jobs that are executed in parallel.
With all of that in mind, every tool is only powerful if it’s used in the right way. AirFlow can easily run into performance issues if the pipeline and its underlying tasks aren’t written in the way it was intended to. As there are countless beginner tutorials online, we plan not to focus on showing you how to write DAGs in AirFlow, but instead assume that you have a basic understanding of it. In this article we will be sharing with you tips and tricks on how to use AirFlow to its full potential.
1. How to use other languages
While the DAG itself has to be written in Python and this is unavoidable, the orchestrator should never force us to write our jobs in a specific language. For Python and Bash there are the respective PythonOperator and BashOperator but other languages potentially don’t have their dedicated operators. So how to circumvent this? Simple – use the DockerOperator.
With the DockerOperator you can easily specify everything about the environment needed to run your code, even what exact version of compiler or interpreter. You can use both public DockerHub or AWS ECR images, or even feed it private images via the docker_conn_id argument. If you use something all the time, you can even define your own Operator by overriding this one. This is even useful for Python code: if you don’t want to bloat your AirFlow setup with lots of packages or depend on the version of python that AirFlow is running on, you can easily set up a container with your requirements and run custom Python without exposing your AirFlow setup to it and fearing package conflicts.
For example, if you need to run some Haskell code you can simply state what the container is and give it a path to your specific script:
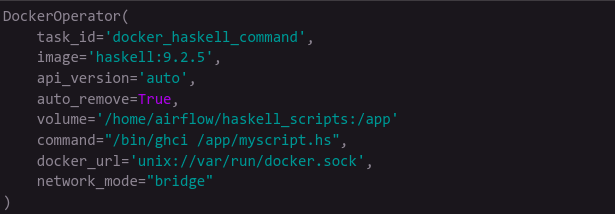
If you’re using the Kubernetes Executor to run all your tasks in a kubernetes cluster, the KubernetesPodOperator is an excellent way of achieving the same goal and cutting out the middleman. Besides being able to develop your different functionalities as separate projects and by just defining a image that runs your code, you can also control the resources that pod is being allocated to, define weights and priorities to specific tasks getting allocated resources, and even have XCom communication by writing results into a specific file: /airflow/xcom/return.json.
2. How to communicate between tasks
Because complete isolation between the tasks in our pipeline is an unreasonable expectation, airflow offers various ways for inter-task communication. AirFlow Variables are a sort of global variable space for all AirFlow DAGs. You can both set them from the UI, pull them from the environment or just set them in tasks. You can even connect your AirFlow instance to the AWS Parameter Store and pull values from there as encrypted secrets. Designed for storing string values, you can even retrieve a json formatted string directly as a dict and pass subvalues as jinja templates.
But as any good programmer knows, over utilizing global variables can be dangerous and sometimes we want to be able to pass values that have the scope of the DAG run. For this utility AirFlow made XCom as a way for our jobs to pass information directly to each other. When the information is just a short string, this is perfect! When passing something different though, this can potentially cause a headache.
Let’s say, we want to pass a number. Because pulling from XCom by default returns a string we have to cast it to an int. This is simple, but forces us to worry about types, which is not very pythonic. Instead, as of AirFlow 2.1, you can pass render_template_as_native_obj = True to the DAG constructor and it starts treating your passed objects as the exact object that has been pushed. But that isn’t the end of the problems.
You should NEVER pass large objects to XCom because the AirFlow backend DB stores all values passed permanently, and you risk bloating the backend and slowing it down (Variables don’t have this issue, the DB only always keeps track of the latest value only). Even a dictionary can potentially fill up the DB if the DAG is ran a sufficient amount of times. If passing large objects is unavoidable, you should do it with some other service: AWS S3 or redis are a good solution, but you have to then make sure that the objects or resource is deleted after it’s not needed any more. Also, you have to make the pathing specific to the DAG run to avoid concurrency issues if your DAG can be run multiple times in parallel. A simple way to do this is to implement your own XCom, with the exact logic you need and using whatever tool you intend for job communication.
3. How to split large jobs
Let’s say as part of your ETL pipeline you have to process large amounts of data. Doing it as just one job makes no sense, especially if your AirFlow is set up to run in a cluster. The best way of doing this is to not do it at all: instead use some other tool for distributed batch processing like Apache Spark and use AirFlow just to schedule the operation. If this is not available, try to avoid any hard coding and evaluate as much as possible during runtime. If we don’t know the number of batches we’ll end up with, AirFlow 2.3 offers us dynamic task making.
This way, we can determine at runtime how many instances of our job we need and run them in parallel. This avoids us having to make specific DAGs for each use case, or having to run way more tasks than we need or running empty tasks and handling this ourselves. AirFlow was not designed to be an ETL tool, so doing transformations in it can be painful, but if used right and in coordination with other tools this can be easily achieved.
4. How to reuse code and DAGs
The property of any good code is modularity and reusability, and the same is true with DAGs. To increase reusability of the DAG we can pass it the params argument in the constructor with a dict of default values, and even enforce passing of an argument by templating it with dag_runc.conf instead of params. If written this way we can easily trigger this DAG from other ones with the TriggerDagRunOperator. While it’s easy to look at DAGs as unconnected pieces of code, the best way to orchestrate everything is by implementing it as a sequence of triggers. We can distinguish between things that are a part of our pipeline and things that happen after our pipeline with the wait_for_completion boolean flag. We can then pass the dag name and desired config via the respective dag_id and conf parameters.
But what if something doesn’t make sense on its own, only as part of a pipeline? The old way was by defining SubDAGs in a function and then calling them to generate the desired task pattern, but this is pretty much just a legacy option that introduces a lot of performance issues if used. At the moment, AirFlow has TaskGroups as a functionality, which not only allows us to define task patterns easily and reuse them, but also makes it visually simpler by reducing everything to only one field at a time that is expandable on click.